DB 개념잡기
먼저 데이터와 정보의 구별 :
데이터를 가공해 정보가 생기는 것. 즉 데이터는 어떤 필요를 위해 수집해 놓은 것으로 아직 특정 사용 목적을 위해 정제되지 않은 상태이다. 가공하는 경우 정보가 되는데 이 정보가 다시 지식 및 지혜 개념으로 확장되기도 한다.
그러면 사용을 염두해 두고 보관하는 데이터를 어떻게 관리해야 할까?
- 효율적인 데이터 관리는 통합되어야 하고, 일관적이어야하고, 누락과 중복이 없어야하며, 여러 사용자가 실시간으로 사용할 수 있어야한다.
위와 같이 구조화된 데이터의 집합을 데이터베이스라고 정의한다. 그리고 이러한 데이터베이스의 관리를 DataBase
Management System, 즉 DBMS라고 합니다.
실무에서는 DB와 DBMS를 구별하지는 않습니다. 즉, 특정 응용프로그램이 DB로 접근하여 데이터를 사용하는 경우 중간다리 역할이 DBMS가 되고 보통은 DB 담당자가 다리 역할까지 수행하게 됩니다.
DB의 장점은 흔히 우리가 사용하는 파일 시스템과 비료해 볼 수 있습니다.
Flat File Structure라고 하는데, 어떤 파일은 학생들의 신상과 기타 정보가, 다른 파일에는 장학금신청 결과값들이 있을 수 있는데 이 둘이 이어져 있지 않은 불편이 생깁니다.
하지만 DB를 통한다면 둘이 연결될수가 있는데요, 이게 통합되어 관리하는 장점이라고 쉽게 예를 들수 있습니다.
그렇다면, 이제 데이터를 관리하는 방법, 즉 데이터의 모델에는 어떤것들이 있을까요?
기본적으로 데이터를 컴퓨터에 저장하는 방식은 계층형(hierarchical), 네트워크형(Network), 관계형(Relational), 객체 지향형(Object Oriented)이 있습니다.
과거(1960~1980)에 가장 빈번하게 사용된 방법은 계층형과 네트워크형입니다.
쉽게 말하면 계층형은, 소위 우리가 알고 있는 Tree형식으로 밑으로 가지쳐나가는 방법입니다.
즉, 데이터 관련성을 계층으로 (1:N)으로 나누는 건데요,
사람 -> 남자 / 여자
남자 / 여자 -> 10대 / 20대 /30대 이런 방식으로 말이죠.

단, 이 방법에는 비효율이 있습니다. 문제는 1 -> N 이라는 형태로 자식 객체는 하나의 부모객체 뿐이 가지지 못하기 때문에 중복이라는 비효율이 발생하죠.
이러한 문제를 극복한게 네트워크형으로, 네트워크 형은 1:N이 파괴되어 여러 부모를 둘 수 있습니다.
1980년대 이후에는 객체 지향형 DB가 등장하는데요, 저희가 알고 있는 객체 지향형 프로그램 마냥, 데이터를 독립된 객체로 구성하는 겁니다.
객체지향 하면 따라오는 단어들이 있죠, 상속과 오버라이드로 DB에서도 가능해지는 겁니다.
아직은 객체지향형이 확 이해되지 않을 수 있는데요, 사실 그렇기에 잘 사용되지 않았습니다.
하지만, 다음에 설명드릴 관계형 모델과 객체지향 모델은 결합되어 사용되는 경우가 가장 많습니다.
가장 중요하다고 알려진 관계형 모델은,
쉽게 말하면 "관계"를 중요하게 여깁니다.
즉 여러 데이터들이 분류되어 있다면, 이 데이터들이 서로 어떻게 이어지는 것인지가 포인트인 것이죠.
예를 들면,
학생에 대한 정보로, [학생번호, 이름, 전공, 학년, 학과, 학과 위치] 이렇게 있다고 한다면,
학과에 대응되는 학과 위치 두가지 정보가 여러차례 중복되는 것이 보입니다.
그러면 별도의 코드, 혹은 식별 번호를 만들어 예를 들면 01번 경영대학 - 강남, 이렇게 대체하여 데이터를 줄일 수 있게 됩니다.
말로만 정의 및 설명하니 이해가 잘 안되는데 예를 통해 정확한 구성단위를 다시 정의해 보겠습니다.
먼저 개체라는 단위를 설명드리겠습니다.
개체(Entity)는 DB에서 데이터화 하려는 사물, 개념의 정보단위입니다. 즉, 관계형 데이터베이스의 테이블로 상응하여 이해하면 되겠습니다. 그리고 이 테이블은 Relation으로 표기되기도 합니다.
아래는 하나의 관계형 DB 예시인데요, 각각의 네모 테이블이 결국 하나의 entity, 개체입니다.
각각의 개체, 즉 테이블은 다시 속성을 지니게 됩니다.
속성은 개체를 구성하는 가장 작은 논리적인 단위로 생각하면 됩니다. 데이터의 종류, 특성, 상태 등을 정의하고, 관계형 DB의 열 개념과 대응됩니다. 즉, 더 쉽게 생각하면 테이블 안에 내용물들에 대한 성격이 곧 속성이다 라고 보면 됩니다.
예를 들면,
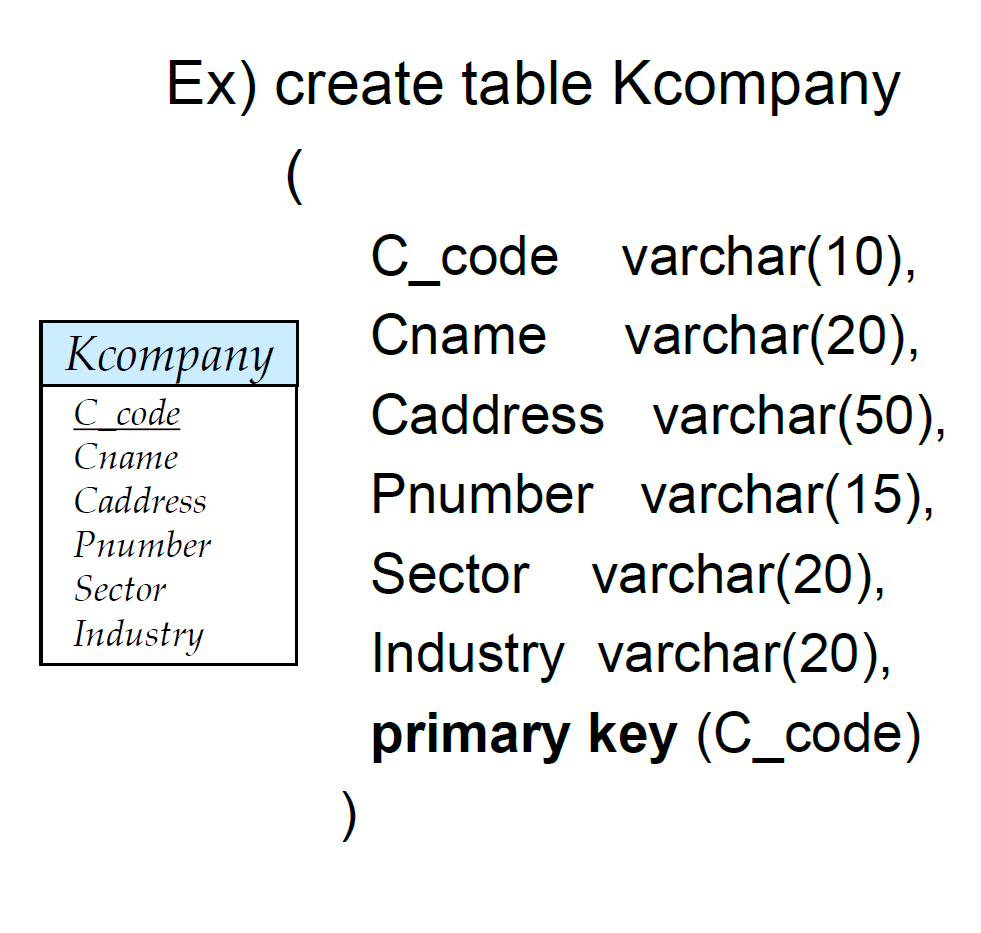
위 개체 company K 안에 회사의 코드, 이름, 주소, 번호, 산업, 산업코드가 있을 수 있죠. 그리고 다시 각각의 데이터의 타입이 정의되는거죠. 문자로 구성되어 있다. 아니면 숫자 20자리로 구성되어 있다.
그러면 마지막으로 관계는 무엇일까요?
관계는 테이블들을 연결하는 것을 말합니다. 즉 위 그림에서 화살표들이라고 생각하면 쉽게 이해할수 있습니다. 그러면 그냥 무작정 화살표만 그리면 되는거냐? 그게 아닙니다. 두개의 테이블들을 이어붙이는 Key 라는 열이 필요한거죠.
지금 위 예시, 컴퍼니 K에서는 primary key로 회사 코드가 지정되어 있는거죠.
(*조금 더 자세히 들어가면, 기본키(Primary Key)와 외래키(Foriegn Key)로 다시 구별됩니다.)
- 기본키는 중복이 없어야합니다. 유일한 값이고 또 공백(Null)을 가질 수 없죠. 하나의 개체 안에 하나의 기본키만 가능합니다.
-외래키는 개체들, 즉 테이블들을 이어붙이는 키라고 생각하면 됩니다. 그리고 기본키와는 달리 하나의 개체 안에 여러개의 외래키를 지정할 수 있습니다. 그리고 중복 값과 Null도 허용됩니다.
예를 들면 학생 식별 번호를 기준으로 여러가지 개체들이 만들어질 수 있는거죠. 하나는 학생의 장학금, 하나는 성적, 하나는 수강 수업 등등 이렇게 말이죠.
여기까지 논의한 내용은 DB, DBMS, 관리 모델이 어떤게 있는지였습니다.
가장 많이 사용되는 모델은 관계형 모델이라고 언급하였습니다. 그리고 그것을 RDBMS라고 이야기합니다. 즉 관계형 데이터베이즈 관리인거죠.
그러면, SQL은 무엇일까요?
SQL (Structured Query Language), 시퀄 혹은 에스큐엘이라고 읽습니다.
SQL이 그래서 뭐냐? 그냥 DBMS를 하기 위한 컴퓨터와 대화하는 방법입니다.
즉, 데이터에 관해서 묻고 대답을 얻는 방법인거죠.
SQL은 다시 여러 종류로 나뉘어집니다. 복잡해 보일 수 있으나, 쉽게 말하면, 우리가 말하는 한글에 있어 자음과 모음으로 나뉘듯 SQL도 다시 그 안에서 분류가 되는 것일 뿐입니다.
(1) DQL(Data Query Language)
RDBMS에 저장된 데이터를 원하는 방식으로 조회하는 명령어들
(2)DML(Data Management Language)
RDBMS 내 테이블(개체)를 저장, 수정, 삭제하는 명령어들
(3)DDL(Data Definition Language)
RDBMS 내 데이터관리를 위해 테이블을 포함 여러 객체를 생성,수정,삭제 하는 명령어들
(4)TCL(Transaction Control Language)
트랜잭션 데이터의 영구 저장 취소 등과 관련된 명령어들
(5)DCL(Data Control Language)
데이터 사용 권한과 관련된 명령어들
위와 같이 소분류 되는데요 각각의 언어에 대해서는 다음에 알아보겠습니다!
(2)편은 아래 링크!
https://carryon430.tistory.com/18
오라클 데이터베이스 입문 (2) : 관계형 DB란? 기본키, 외래키, 복합키, 대체키, 후보키, Key란?
1편 DB의 기초, 못읽어 보신분들은 읽고 오세요!! -----> https://carryon430.tistory.com/17 오라클 데이터베이스 입문 (1) : DB이란? DBMS이란? SQL이란? DB 개념잡기 먼저 데이터와 정보의 구별 : 데이터를 가..
carryon430.tistory.com
'Programming > 데이터베이스 \ 오라클' 카테고리의 다른 글
| 오라클 데이터베이스 입문 (6) : SCOTT 계정 활용, DISTINCT, ALL, 별칭 AS, ORDER BY, WHERE, AND, OR, 논리연산자 (0) | 2022.08.02 |
|---|---|
| 오라클 데이터베이스 입문 (5) : SQL Developer 사용 (0) | 2022.07.28 |
| 오라클 데이터베이스 입문 (4) : DBA 접속, 계정 생성 (0) | 2022.07.25 |
| 오라클 데이터베이스 입문 (3) : 오라클 설치, 오라클 11g(11.2) 버전 설치, 오라클 과거 버전 다운로드 (1) | 2022.07.24 |
| 오라클 데이터베이스 입문 (2) : 관계형 DB란? 기본키, 외래키, 복합키, 대체키, 후보키, Key란? (0) | 2022.07.24 |




댓글