저는 개인적으로 머신러닝과 딥러닝을 금융 시장에 적용하는 것에 굉장히 회의적이었습니다, 그리고 그렇기에 관심을 두지 않았습니다. 저와 같이 회의적인 분들이 있는 반면 열정적으로 해당 분야를 연구하고 또 매일 같이 전략을 테스트하는 분들도 계십니다. 제가 회의적이었던 이유는 아래와 같은 이유들 때문이었습니다.
(1) Black Box : 흔히 알려져 있는 이유로 분석가가 왜 그런 결론이 나왔는지 명확하게 설명하지 못하는 문제. 물론 이후 상자를 열어볼 수 있는 방향으로 또 다시 발전하고 있는 것으로 알고 있습니다.
---> 이러한 이유에 대해 특히 좋지 않게 보았던 이유로는 결론적으로 최종 의사결정권자의 설득이 불가능하다면 논의 자체가 불가하기 때문입니다.
(2) 금융 데이터의 특성 : (저에게 가장 큰 이유는 데이터였습니다.) 금융 데이터의 특징은 데이터를 통제하지 못하는 점입니다. 그리고 다시 동일한 상황을 재현하여 데이터를 생성할 수도 없습니다. 그리고 그날 그날의 데이터는, 단 하나의 샘플 뿐입니다. 즉, 날짜를 row로 하는 표를 만든다고 생각하면 해달 일자의 row 개수는 1개인거죠..
예를 조금 더 구체적으로 들어보겠습니다. 일반적으로 경제 지표들의 경우 월별 혹은 분기별로 발표되는 지표들이 많습니다. 물론 주/격주 단위의 짧은 주기도 있습니다. 월별을 기준으로 그리고 1980년도부터 그래도 신뢰성 있는 데이터들이 존재한다고 생각해보면 43개 년도의 데이터 43*12 = 516개 입니다... 정말 적은 숫자라고 생각합니다. 물론.. 데이터 재생산 등 다시 여러가지 방법들이 존재하는 것은 알고 있지만 저는 회의적이었습니다. 차원의 저주와 파라미터가 늘어나 복잡도가 올라가는 경우 더욱 모델에 문제가 많아지게 됩니다. 굉장히 많은 경제학/계량경제학 대가들이 비판하는 부분입니다.
3년 전 즈음 설득 되었던 생각들이었고... (지금 돌이켜 보면 조금은 근시안적이고 지식이 짧았기에 갖게 된 나의 생각이지 않을까 싶기도 합니다...) 저는 이러한 생각들이 자리잡아 머신러닝 분야에 크게 관심을 갖지 않게 되었습니다. 하지만 위에 언급한 논문을 읽고... 생각이 조금씩 조금씩 바뀌고 있습니다. 그리고 바뀌게 되는 이유는 아래와 같은 이유들 때문입니다.
(1) 예측력만 놓고 본다면 ML이 더 뛰어나다.
(2) 어차피 기존의 팩터 투자도 그냥 상관관계를 기반으로 하는 인과관계에 대한 이슈가 해소되지 않은 지식과 이론이다.
저에게 있어서 2번은 굉장히 큰 충격이었습니다. 이걸 이제서야 알게 된 것에 대해 굉장히 부끄럽고 혹시라도 저와 같은 분들이 계실까봐 일찍이 관심을 가지고 들여다 보는 계기가 되기를 바라는 마음에 글을 계속 이어가봅니다. 2번을 다른 말로 더욱 공격적이게 적어보면
"Fama French 모형 그거 다 잘못된거야" 입니다.
금융 전공을 한 학생이면 학부부터 반드시 배우게 되는 이론들입니다... 금융의 상당 부분이 해당 지식을 받아들이고 그 위에 쌓아올린 모델 논문들만 몇 십만개는 그냥 넘지 않을까요?
결론부터 말씀드리면, 저자 Prado는 현재까지의 팩터 투자에 대한 연구, 즉 Low Vol, Small Cap, MoM 대표적인 팩터들 모두 그저 단순한 associational claim에 불과하다고 지적합니다. 즉, Y~X 라는 관계를 분석함에 있어 단순히 상관관계에 기반을 두고 주장을 하는 것에 불과하고 가장 핵심이 되는 Causation에 대한 분석이 부재하다고 지적합니다.
Association 과 Causation의 차이를 강조하는 이유는 무엇일까요?
먼저 Association, 뭔가 관계가 있다라고 하는 것은 무엇일까요?
확률 변수 X와 Y에 대하여, 독립인 경우 P(X=x)*P(Y=y) = P(X=x,Y=y) 라고 합니다. 반대로 co-dependent 하다면, 독립 조건이 성립하지 않는 것입니다. 어떠한 관계가 있다고 하면, X 혹은 Y 값 하나를 관찰하게 되면 다른 상대 값에 대해 어떤 정보를 전달 해주게 됩니다. 익숙한 표현 P(Y=y | X=x) != P(Y=y) 입니다.
문제는 위 식이 X와 Y의 인과관계를 설명해주지 못합니다. 상관관계가 있다고 인과관계를 이야기하는 것은 아니라는 표현을 많이 들어보셨을겁니다. 하지만 반대로, 인과관계가 있다면 상관관계는 있다고 하죠.
그렇다면 인과관계는 어떻게 이해해야할까요?
먼저 인과관계라는 것에 대해서 수학적으로 생각해보면, X가 Y의 원인이 되기 위해서는 Y should be a function of X, Y(X)라고 저자는 이야기 합니다. 다시 표현해 보면, 인과 관계가 있는 경우에는 Setting the value of X to x increases likelihood that Y will take the value y 입니다. 물론 당연히 우리는 이러한 식을 알 수 없기 때문에 관찰을 통해서 추론해내야 합니다. 그렇기에 저자는 do-calculus 라는 수학 영역을 배경으로 하는 Causal Inference의 기반이 되는 수학 영역으로 논의를 확장해갑니다. Do-Calculus 를 이해하고 싶으시다면 아래의 bullet point를 찾아보시기 바랍니다.
(ㄱ) Pearl, J. (2009): Causality: Models, reasoning and inference. Cambridge, 2nd edition (ㄴ) Pearl, J., M. Glymour, and N. Jewell (2016): Causal Inference in Statistics: A Primer. Wiley, 1st edition. (ㄷ) Neal, B. (2020): Introduction to Causal Inference: From a Machine Learning Perspective. Course lecture notes (https://www.bradyneal.com/causal-inference-course )
여러 차례 prado paper의 첫번째 파트를 읽은 후 제가 이해한 바에 따르면 Confounding Factor 를 통제하기 위해 조건부 확률과는 미묘하게 다른 DO-Operator를 적용한 조건부 확률을 소개합니다.
난해할 수 있지만 정말 쉽게 생각해보면, 경제학자들이 항상 입에 달고 사는 어쓤... Ceteris paribus (holding other things constant) 입니다. 즉, DO[X=x]는 X를 고정값으로 고정하는 것입니다. 그리고 DO[X=x] 고정을 하면, P[Y=y] 되는 확률이 올라간다 입니다.
인과관계라는 것이 무엇인지를 정확히 이해하는 것이 1단계입니다. 그러면 금융 데이터는 이 DO-Operator를 현실에서 통제하여 데이터를 만들 수 있나요? 효과 라는 것을 수학적으로 표현해 보면, Average Treatment Effect (ATE)
로 표현해 볼 수 있습니다. 문제는 우리가 관찰하는 조건부 확률은 아래와 같아집니다.
ATT(Average Treatment effect on the Treated)와 SSB(Self-Selection-Bias)이고 현실 세계에서는 SSB라는 오류가 함께 포함될 수 밖에 없습니다 왜냐하면 재현해 내는 것이 금융 데이터는 불가능합니다.
위 기대값은 X=x0로 setting 되어 있는데 사실 일어난 X값은 X=x1 일때의 Y의 기대값으로 이러한 상황을 우리는 만들어 낼 수가 없죠 금융데이터는... SSB를 제거하기 위한 연구 방법론들이 존재합니다. Inteverntional, Natural, Simulated 로 분류되는 실헙들이 존재합니다.
Interventional = 우리가 아는 Randomized Control Group으로 변수를 직접 통제하는 방식.
Natural은 윤리적이나 물리적으로 과학자들이 개입이 어려운 환경일때 자연적으로 통제가 이루어지게끔 하는 방식. 즉 자연적으로 ceteris paribus가 되도록 하는거고 이게 이 실험의 관건. 더 디테일한 방법들로는 (1) regression discontinuity design (RDD); (2) crossover studies (COS); and (3) difference-in-differences (DID) studies 같은게 있음.
Simulated 같은 경우 사실상 Do-operation을 구현해 낼 수 없으니, 다만 할 수 있는게, X가 얼마나 강하게 Y에 영향을 주는지를 이용하는 방법임(strength of the Causal Effect). constraint-based algorithms, score-based algorithms, functional causal models (FCMs) 같은게 있음.
위와 같은 이유들로 Causation과 Association은 다르고, 금융데이터는 데이터를 통제하는 다른 연구들의 접근법들마저 어렵습니다.
그러면 지금까지의 연구들은 무엇인가? 수 많은 수학자들과 협업하고 오늘날까지 쌓아온 지식들이 논리가 없을리는 없을텐데....
우리가 익숙한 회귀분석을 이야기로 들기 시작합니다.
Joint Distribution 이라는 개념에서 출발하는 경우 한다고 생각하면 Association을 의미하는 것이고, Joint Distribution (X,Y), Y~X 나 X~Y 의 관계식이 성립해야합니다. 즉, 방향성이 없는 관계인거죠.
𝑌_𝑡 =𝛽_0+𝛽_1𝑋_𝑡+𝜀_𝑡 𝑋_𝑡=𝛾_0+𝛾_1𝑌_𝑡+𝜁_𝑡
그렇다면 𝛾̂_0=−𝛽̂_0/𝛽̂_1 그리고 𝛾̂_1=1/𝛽̂_1, and 𝜁̂=−𝜀̂/𝛽̂_1 와 같은 관계가 성립해야 하는 것이죠. 문제는 Least Square Estimate 은 이것이 성립하지 않습니다. 그러면 LSE는 Join Distribution 을 염두한 Association 측정이 아닌 것이죠.
그러면 LSE는 무엇을 염두해 두는 모형인걸까요? 저자는 결국 Causal Relationship을 의미한다고 합니다. 그리고 저희가 많이 배운 그리고 저 또한 잊고 간과했었던 LSE 모형의 핵심 가정을 언급합니다.
Y = XB+e 를 표현하면,
𝐸[𝛽̂_hat|𝑋]=𝛽 이기 위해서는 𝐸[𝜀|𝑋]=0 이어야 합니다. 이러한 조건을 Exogeneity Condition 이라고 합니다. 그리고 조건 충족을 위해 보통 두가지 접근법이 존재하는데 Implicit / Explicit 이 있습니다.
Implicit Exogeneity 는 error term을 아래와 같이 정의함. 그러면 𝐸[𝜀|𝑋] 를 0으로 증명할 수가 있게 됩니다. 이 경우 𝐸[𝑌|𝑋]=𝑌−𝜀=𝑋𝛽 이지만 해석의 경우 단순히 association할수 밖에 없게 됩니다. 그리고 애초에 의도하였던 인과관계를 전달하지 못합니다.
Explicit Exogeneity는 error term에 대한 정의를 Y에게 영향을 주는 X외 모든 것으로 동시에 X와 독립적이라 가정합니다. 그리고 이 경우에는 인과관계가 유효하게 해석되고 𝐸[𝑌|𝑑𝑜[𝑋]]=𝑋𝛽 가 성립하게 됩니다. 오늘 날까지의 연구들이 기반으로 하는 가정입니다. 그리고 저자는 여기에 Do-Operator를 사용해 재표현해 봅니다. 이러한 데이터 세트는 앞서 설명한 Natural experiment에 해당하고 얼마나 확실하게 모델을 정교하게 만들었는지가 큰 관건이 되는 경우입니다.
저자는 중반부에 들어서며 Fama French 를 언급하기 시작합니다. 그리고 연구의 설계 최초에 Association 관계가 아닌 Causal 관계를 염두해 둔 연구임을 이야기합니다. 그리고 많은 통계적 오류들을 나열해 나갑니다. 또한 단순히 Association만이 중요한 요소였다면 머신러닝이 월등히 높은 예측력을 주는 기법들이 많음을 이야기합니다. 즉, 인과관계에 초점을 둔 것이 아니라면 훨씬 좋은 다른 접근 법들이 있는데 왜 굳이 LSE 접근을 사용했냐 입니다.
결론적으로는 Explicit Exogeneity 라는 조건에 모든게 달려 있는 것이 팩터에 대한 연구이나, 이 조건을 충족하였다고 보기에는 무리가 존재한다 입니다. 수 많은 Bias를 내포하는 연구를 그 동안 과학적 근거 없이 받아들여 왔다고 비판합니다. 그리고 과학적 발견의 Falsification Process를 강조합니다.
나아가 금융 산업이 학계에 미치는 강력한 영향에 대해서도 비판하고 이제부터서라도 Causal Inference 에 대한 연구를 나아가야 한다고 강조합니다.
많은 부분들이 생략되어 있고 또한 제 내공이 부족해 설명력이 떨어지는 요약일 수 있습니다. 하지만 저는 paper를 읽고, 아니 어차피 다 잘못된거면... 그냥 예측력 높은 방법이 Best 아닐까?.. 싶었다. 어차피 누가 맞는지도 모르는 영역에서 다 같이 헤엄치고 있다면... 팩터 투자도 다 오류 투성이면 차원의 오류쯤이야 아닌가 말이다.



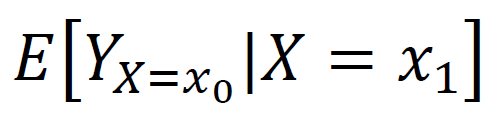







댓글